如果对人工智能稍有了解的小伙伴们,或多或少都听过反向传播算法这个名词,但实际上BP到底是什么?它有着怎样的魅力与优势?本文发布于 offconvex.org,作者 Sanjeev Arora与 Tengyu Ma,雷锋网对此进行了编译,未经许可不得转载。
目前网络上关于反向传播算法的教程已经很多,那我们还有必要再写一份教程吗?答案是‘需要’。
为什么这么说呢?我们教员Sanjeev最近要给本科生上一门人工智能的课,尽管网上有很多反向传播算法的教程,但他却找不到一份令他满意的教程,因此我们决定自己写一份关于反向传播算法的教程,介绍一下反向传播算法的历史背景、原理、以及一些最新研究成果。
PS:本文默认读者具备一定的基础知识(如了解梯度下降、神经网络等概念)。
一、什么是反向传播算法?反向传播算法是训练神经网络的经典算法。在20世纪70年代到80年代被多次重新定义。它的一些算法思想来自于60年代的控制理论。
在输入数据固定的情况下、反向传播算法利用神经网络的输出敏感度来快速计算出神经网络中的各种超参数。尤其重要的是,它计算输出f对所有的参数w的偏微分,即如下所示:?f/?wi,f代表神经元的输出,wi是函数f的第i个参数。参数wi代表网络的中边的权重或者神经元的阈值,神经元的激活函数具体细节并不重要,它可以是非线性函数Sigmoid或RELU。这样就可以得到f相对于网络参数的梯度?f ,有了这个梯度,我们就可以使用梯度下降法对网络进行训练,即每次沿着梯度的负方向(??f)移动一小步,不断重复,直到网络输出误差最小。
在神经网络训练过程中,我们需要注意的是,反向传播算法不仅需要准确计算梯度。还需要使用一些小技巧对我们的网络进行训练。理解反向传播算法可以帮助我们理解那些在神经网络训练过程中使用的小技巧。
反向传播算法之所以重要,是因为它的效率高。假设对一个节点求偏导需要的时间为单位时间,运算时间呈线性关系,那么网络的时间复杂度如下式所示:O(Network Size)=O(V+E),V为节点数、E为连接边数。这里我们唯一需要用的计算方法就是链式法则,但应用链式法则会增加我们二次计算的时间,由于有成千上万的参数需要二次计算,所以效率就不会很高。为了提高反向传播算法的效率,我们通过高度并行的向量,利用GPU进行计算。
注:业内人士可能已经注意到在标准的神经网络训练中,我们实际上关心的是训练损失函数的梯度,这是一个与网络输出有关的简单函数,但是上文所讲的更具有普遍意义,因为神经网络是可以增加新的输出节点的,此时我们要求的就是新的网络输出与网络超参数的偏微分。
二、问题设置反向传播算法适用于有向非循环网络,为了不失一般性,非循环神经网络可以看做是一个多层神经网络,第t+1层神经元的输入来自于第t层及其下层。我们使用f表示网络输出,在本文中我们认为神经网络是一个上下结构,底部为输入,顶部为输出。
规则1:为了先计算出参数梯度,先求出 ?f/?u ,即表示输出f对节点u的偏微分。
我们使用规则1来简化节点偏微分计算。下面我将具体说一下?f/?u的含义。我们做如下假设,先删除节点u的所有输入节点。然后保持网络中的参数不变。现在我们改变u的值,此时与u相连的高层神经元也会受到影响,在这些高层节点中,输出f也会受到影响。那么此时?f/?u就表示当节点u变化时,节点f的变化率。
规则1就是链式法则的直接应用,如下图所示,u是节点 z1,…,zm的加权求和,即u=w1*z1+?+wn*zn,然后通过链式法则对w1求偏导数,具体如下:
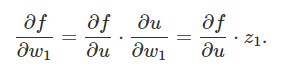
由上式所示,只有先计算?f/?u,然后才能计算?f/?w1。
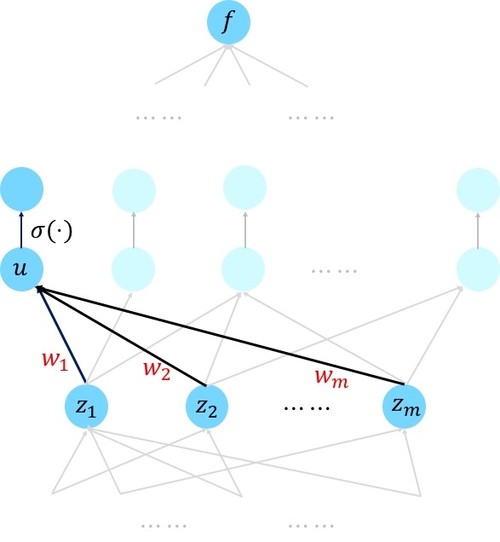
为了计算节点的偏微分,我们先回忆一下多元链式法则,多元链式法则常用来描述偏微分之间的关系。 即假设f是关于变量u1,…,un的函数,而u1,…,un又都是关于变量z的函数,那么f关于z的偏导数如下:
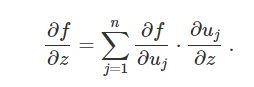
这是链式法则2的一般式,是链式法则的1的子式。这个链式法则很适合我们的反向传播算法。下图就是一个符合多元链式法则的神经网络示意图。
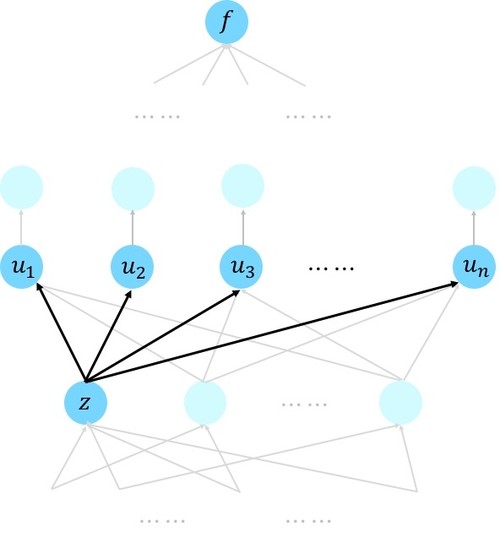
如上图所示,先计算f相对于u1,…,un的偏导数,然后将这些偏导数按权重线性相加,得到f对z的偏导数。这个权重就是u1,…,un对z的偏导,即?uj/?z。此时问题来了,我么怎么衡量计算时间呢?为了与教课书中保持一致,我们做如下假设:u节点位于t+1层的,z节点位于t层或t层以下的子节点,此时我们记?u/?z的运算时间为单位时间。
朴素前馈算法(低效算法)我们首先要指出链式法则是包含二次计算的时间。许多作者都不屑于讲这种算法,直接跳过的。这就好比我们在上算法排序课时,老师都是直接讲快速排序的,像那些低效排序算法都是直接跳过不讲的。
朴素算法就是计算节点对ui与uj之间偏导数,在这里节点ui的层级要比uj高。在V*V个节点对的偏导值中包含?f/?ui的值,因为f本身就是一个节点,只不过这个节点比较特殊,它是一个输出节点。
我们以前馈的形式进行计算。我们计算了位于t层及t层以下的所有节点对之间的偏导数,那么位于t+1层的ul对uj的偏导数就等于将所有ui与uj的偏导数进行线性加权相加。固定节点j,其时间复杂度与边的数量成正比,而j是有V个值,此时时间复杂度为O(VE)。
三、反向传播算法(线性时间)反向传播算法如其名所示,就是反向计算偏微分,信息逆向传播,即从神经网络的高层向底层反向传播。
信息协议:节点u通过高层节点获取信息,节点u获取的信息之和记做S。u的低级节点z获取的信息为S??u/?z
很明显,每个节点的计算量与其连接的神经元个数成正比,整个网络的计算量等于所有节点运算时间之和,所有节点被计算两次,故其时间复杂度为O(Network Size)。
我们做如下证明:S等于?f/?z。
证明如下:当z为输出层时,此时?f/?z=?f/?f=1
假如对于t+1层及其高层假设成立,节点u位于t层,它的输出边与t+1层的u1,u2,…,um节点相连,此时节点从某个节点j收到的信息为(?f/?uj)×(?uj/?z),根据链式法则,节点z收到的总信息为S=
四、自动微分

